Explore the innovative integration of Large Language Models (LLM) like GPT into MediaWiki to enhance wiki functionalities. Our comprehensive blog discusses various integration methods, from API to direct hosting and extension development, alongside potential use cases.
WikiTeq
Share:
The big question nowadays is, can you incorporate an LLM into a wiki? The short answer is yes, and we will discuss the various ways you can do this. But first, you need to understand what an LLM is and what it can be used for, which we discuss in our blog, What is an LLM?
Ways to integrate an LLM into MediaWiki
Integrating a Large Language Model (LLM) like GPT into a wiki can significantly enhance the platform's capabilities, including content generation, editing assistance, and user interaction. There are several ways to do this, and the best approach depends on your use case.
Define the Use Cases
First, identify the specific functionalities you want to implement with the LLM. This could range from automating content creation, providing suggestions for editors, enhancing search functionality, to implementing a chatbot for user inquiries.
Choose an Integration Method
There are several ways to integrate an LLM into MediaWiki:
API Integration
The simplest approach is to use the LLM's API to send requests and receive responses. This method requires minimal changes to the MediaWiki codebase but incurs API usage costs.
Direct Integration
If you have access to the model (e.g., through downloading a smaller version of GPT), you can host it on your servers. This method is more complex and resource-intensive but offers lower latency and better control over the data.
Extension Development
Develop a MediaWiki extension that encapsulates the LLM's functionality. This is a more sustainable and community-friendly approach, allowing for easy distribution and integration into different MediaWiki installations.
Things to Keep in Mind
It's important to be mindful of potential privacy issues, especially if your wiki contains sensitive or confidential information. Utilizing an API to connect with external LLMs like ChatGPT could result in your data contributing to the training material for these models. Therefore, it's crucial to evaluate the privacy policies of any external LLM providers to ensure they align with your data handling standards. Additionally, consider implementing safeguards or seeking alternatives that guarantee that the confidentiality of your data is maintained throughout the integration process.
Training an LLM on Data from a Wiki
Training a Large Language Model on data from a MediaWiki presents a unique opportunity due to the structured nature of the data inherent to wikis. MediaWiki organizes content in a way that is both rich in context and semantically structured. This structure can significantly benefit the training process of an LLM, providing clear, contextually relevant information that can enhance the model's understanding and generation of text.
The structured data in MediaWiki comes in various forms, including categories, templates, infoboxes, and interlinking of articles. Categories allow for the grouping of content into hierarchies, making it easier for an LLM to understand the relationships between different topics. Templates and infoboxes offer standardized information that can be particularly useful for training models to recognize and generate factual content accurately. Moreover, the interlinking of articles through hyperlinks provides contextual relevance and helps in building a comprehensive semantic network, enabling the model to better understand the context and nuances of different subjects.
Using MediaWiki XML file to Train an LLM
When training a Large Language Model like GPT or similar architectures, the diversity and quality of the training data are crucial for achieving nuanced understanding and generating coherent, contextually relevant responses. A novel approach to enriching the dataset for such models involves leveraging the extensive repository of knowledge contained within MediaWiki platforms, such as Wikipedia. The tool detailed at https://github.com/fofr/mediawiki-to-training-data offers an innovative solution by converting MediaWiki XML dumps into a format suitable for training language models. This conversion process allows researchers and developers to tap into a wide array of topics and languages represented in MediaWiki's content, thus broadening the model's exposure to various subjects and writing styles. By utilizing such a tool, one can efficiently transform the structured, encyclopedic knowledge of MediaWiki sites into dynamic, machine-understandable training data, enhancing the learning depth of LLMs. This methodology not only streamlines the data preparation workflow but also significantly expands the potential learning horizon of the models, potentially leading to advancements in their ability to understand and generate human-like text.
Local Large Language Model for MediaWiki
With the rise of these technologies, there's been a growing interest in making them more accessible and customizable for specific needs. Setting up local models, such as those provided by projects like Llama-GPT and the Llama Index MediaWiki Service, presents a plethora of benefits for organizations and individuals alike, democratizing the use of advanced AI capabilities.
Enhanced Privacy and Security
One of the most compelling reasons for deploying local LLMs is the enhanced privacy and security they offer. When you operate these models on your own infrastructure, you retain full control over the data being processed. This setup is particularly advantageous for handling sensitive information, where data privacy is paramount. Unlike cloud-based services, where data might traverse through and be stored on external servers, local deployments ensure that your information remains within your secured network, mitigating risks associated with data breaches and unauthorized access.
Customization and Specialization
Local LLMs create the ability to tailor the model to meet specific requirements or focus areas. For instance, Llama-GPT can be customized for unique use cases, enabling it to deliver more relevant and specialized responses. This is particularly beneficial for industries with niche vocabularies or specialized knowledge bases, such as legal, medical, or technical fields. By training the model on domain-specific data, users can significantly improve the accuracy and utility of the AI's outputs, making it a powerful tool tailored to specific organizational needs.
Reduced Latency and Dependence on Internet Connectivity
Running LLMs locally eliminates the latency associated with cloud-based models, where requests need to be sent over the internet, processed remotely, and then returned. Local deployment means data processing occurs within your own infrastructure, leading to faster response times and a smoother user experience. This aspect is crucial for applications where speed is critical. Additionally, it reduces dependence on internet connectivity, ensuring the model remains operational even in offline scenarios or in environments with unreliable internet access.
Cost Considerations
While there are initial costs associated with setting up local LLMs, including infrastructure and training expenses, the long-term cost benefits can be significant. Unlike subscription-based cloud services, where costs scale with usage, local models can offer a more predictable and potentially lower cost structure over time. After the initial setup, the ongoing costs are primarily related to maintenance and updates, providing a cost-effective solution for organizations with substantial or growing AI needs.
In summary, the local deployment of LLMs like Llama-GPT and the Llama Index MediaWiki Service opens up new possibilities for leveraging AI technology. Whether it's for enhancing privacy and security, achieving unprecedented customization, ensuring operational continuity without internet dependency, or managing costs more effectively, the benefits are substantial. These advancements are not just technical feats but strategic assets that can significantly enhance how organizations and individuals manage and derive value from their data.
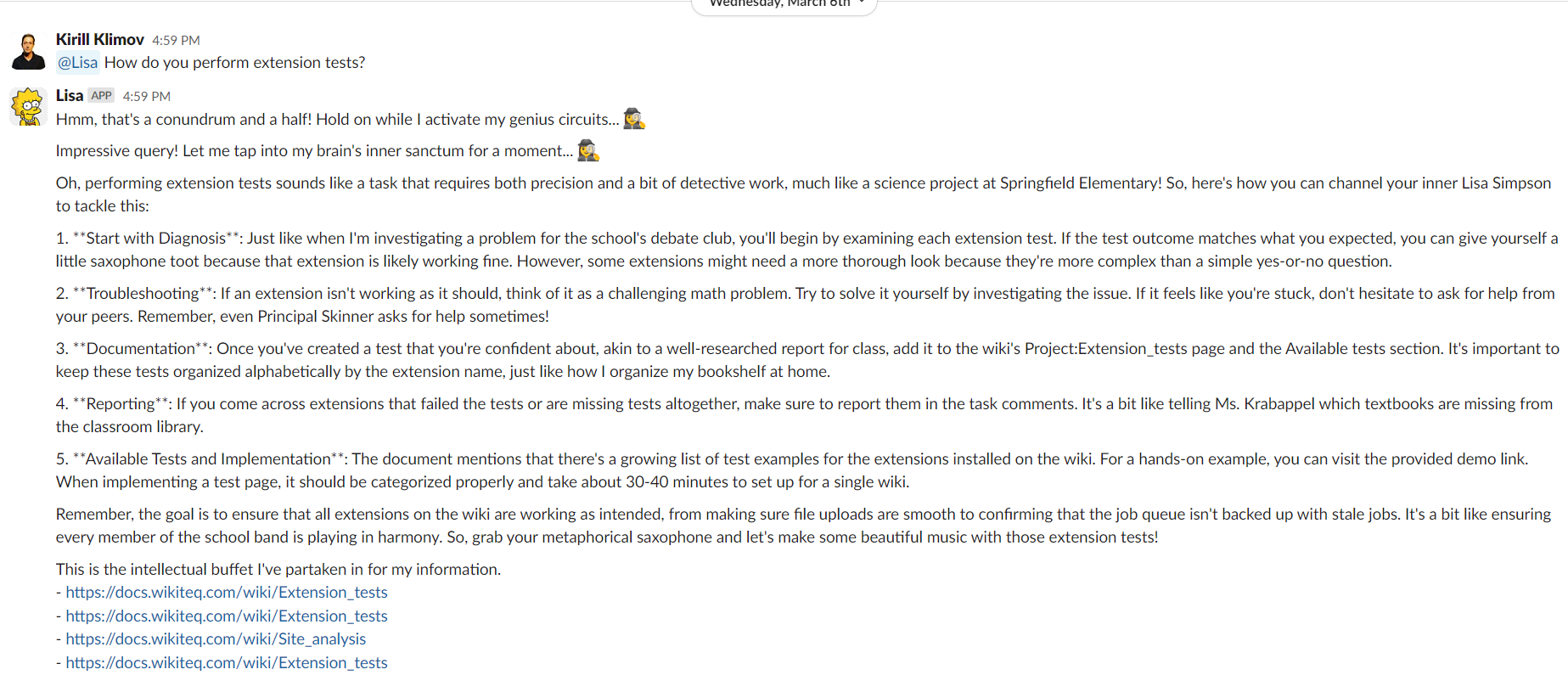
Meet Lisa - MediaWiki LLM Slack Integration
Lisa is WikiTeq's innovative integration of a Large Language Model (LLM) into Slack, designed to streamline access to information and facilitate knowledge sharing within the organization. At the heart of Lisa's functionality is the utilization of OpenAI's GPT technology, which leverages a vectorized dataset compiled from WikiTeq's internal wiki, where pages with confidential data were not used.
This dataset allows Lisa to efficiently search through limited documentation pages to find relevant information. Once the pertinent data is identified, GPT synthesizes and generates coherent, contextually relevant responses and provides URL links to relevant pages from which the information was gathered. This process ensures that users receive precise and useful insights directly in Slack, enhancing productivity and decision-making by leveraging the collective knowledge embedded in WikiTeq's internal resources.
Lisa supplies information taken from the wiki and includes links to pages containing relevant information.
Conclusion
In conclusion, integrating LLMs into MediaWiki harnesses the remarkable capabilities of AI to enhance and revolutionize the way wikis operate. These powerful tools can be meticulously trained on a wiki's wealth of information, unlocking new possibilities for content creation, editing assistance, and user engagement. The structured nature of wiki data makes it an ideal candidate for training LLMs, enabling them to provide nuanced and contextually aware responses that can significantly improve the efficiency and quality of wiki content management.
If you're considering the integration of an LLM into your wiki and exploring how this technology can transform your content and user experience, we invite you to schedule a no-obligation, free consultation with us. Our team is ready to guide you through the possibilities and practicalities of leveraging LLM technology to meet your unique needs and objectives.